Problem 1.1#
Integrated Energy Grids
Problem 1.1. Analysing solar and wind generation time series.
Note
If you have not yet set up Python on your computer, you can execute this tutorial in your browser via Google Colab. Click on the rocket in the top right corner and launch “Colab”. If that doesn’t work download the .ipynb file and import it in Google Colab.
Then install pandas and numpy by executing the following command in a Jupyter cell at the top of the notebook.
!pip install pandas numpy scipy
import pandas as pd
from scipy import fftpack
import numpy as np
import matplotlib.pyplot as plt
Data import#
In this example, wind data from https://zenodo.org/record/3253876#.XSiVOEdS8l0 and solar PV data from https://zenodo.org/record/2613651#.X0kbhDVS-uV is used. The data is downloaded in csv format and saved in the ‘data’ folder. The Pandas package is used as a convenient way of managing the datasets.
For convenience, the column including date information is converted into Datetime and set as index
data_pv = pd.read_csv('data/pv_optimal.csv',sep=';')
data_pv.index = pd.DatetimeIndex(data_pv['utc_time'])
data_wind = pd.read_csv('data/onshore_wind_1979-2017.csv',sep=';')
data_wind.index = pd.DatetimeIndex(data_wind['utc_time'])
The data format can now be analysed using the .head() function to show the first lines of the data set
data_pv.head()
| utc_time | AUT | BEL | BGR | BIH | CHE | CYP | CZE | DEU | DNK | ... | MLT | NLD | NOR | POL | PRT | ROU | SRB | SVK | SVN | SWE | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| utc_time | |||||||||||||||||||||
| 1979-01-01 00:00:00+00:00 | 1979-01-01T00:00:00Z | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1979-01-01 01:00:00+00:00 | 1979-01-01T01:00:00Z | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1979-01-01 02:00:00+00:00 | 1979-01-01T02:00:00Z | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1979-01-01 03:00:00+00:00 | 1979-01-01T03:00:00Z | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1979-01-01 04:00:00+00:00 | 1979-01-01T04:00:00Z | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 33 columns
We will use Denmark as an example for this solution
country = 'DNK'
1) Start by plotting the capacity factors for wind and solar throughout the first two weeks in January and the first two weeks in July. Do this for the most recent year for which you have available data.
data_pv.loc['2017-01-01':'2017-01-14'][country].plot(kind='line', ylabel='Capacity factor \n Solar PV', color='orange')
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 1
----> 1 data_pv.loc['2017-01-01':'2017-01-14'][country].plot(kind='line', ylabel='Capacity factor \n Solar PV', color='orange')
NameError: name 'data_pv' is not defined
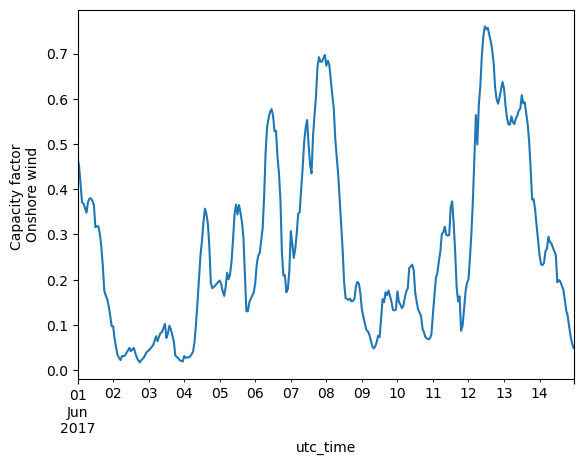
data_pv.loc['2017-06-01':'2017-06-14'][country].plot(kind='line', ylabel='Capacity factor \nSolar PV', color='orange')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nSolar PV'>
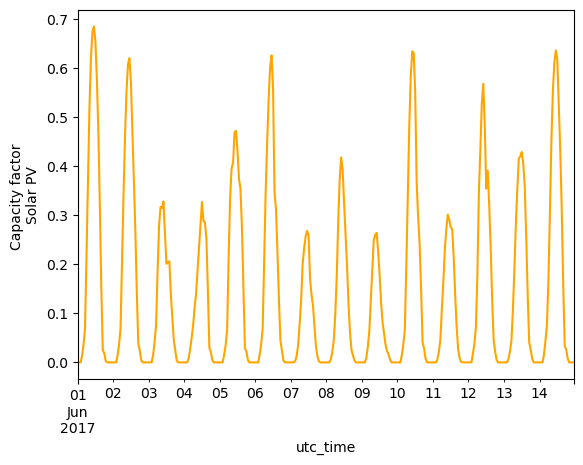
data_wind.loc['2017-01-01':'2017-01-14'][country].plot(kind='line', ylabel='Capacity factor \nOnshore wind')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nOnshore wind'>
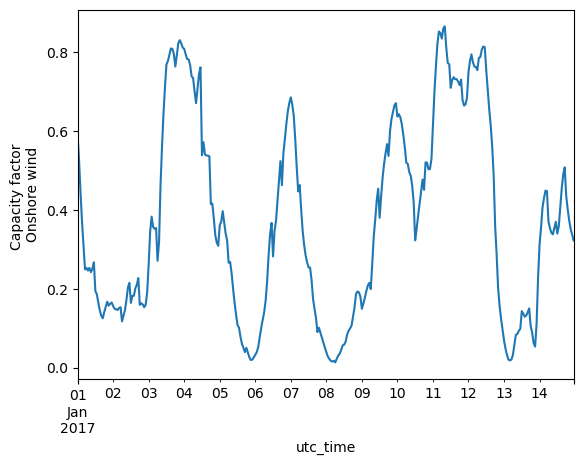
data_wind.loc['2017-06-01':'2017-06-14'][country].plot(kind='line', ylabel='Capacity factor \nOnshore wind')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nOnshore wind'>
2) Calculate the average daily capacity factor and plot them for the entire year. Do the same for weekly and monthly capacity factors. Based on steps 1 and 2, what are the dominant frequencies for every technology?
Daily, weekly and monthly means are calculated using the pandas .groupby function combined with the pandas.Grouper automaticly creationg groups with the desired size.
# Daily
daily_mean_pv = data_pv.loc['2017-01-01':'2017-12-31'][country].resample('D').mean()
daily_mean_wind = data_wind.loc['2017-01-01':'2017-12-31'][country].resample('D').mean()
# Weekly
weekly_mean_pv = data_pv.loc['2017-01-01':'2017-12-31'][country].resample('W').mean()
weekly_mean_wind = data_wind.loc['2017-01-01':'2017-12-31'][country].resample('W').mean()
# Monthly
monthly_mean_pv = data_pv.loc['2017-01-01':'2017-12-31'][country].resample('ME').mean()
monthly_mean_wind = data_wind.loc['2017-01-01':'2017-12-31'][country].resample('ME').mean()
daily_mean_pv.plot(kind='line', ylabel='Capacity factor \nSolar PV', color='orange')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nSolar PV'>
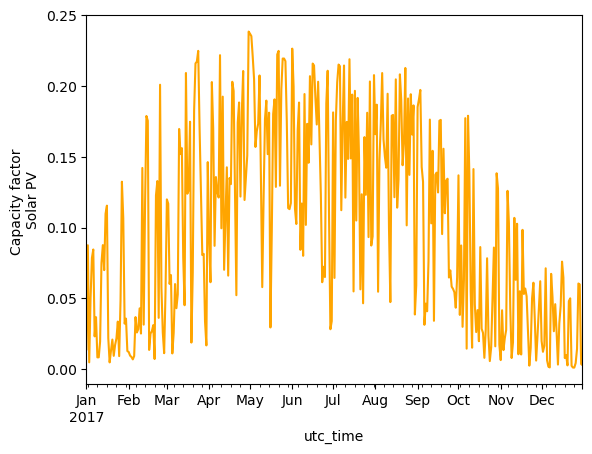
weekly_mean_pv.plot(kind='line', ylabel='Capacity factor \nSolar PV', color='orange')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nSolar PV'>
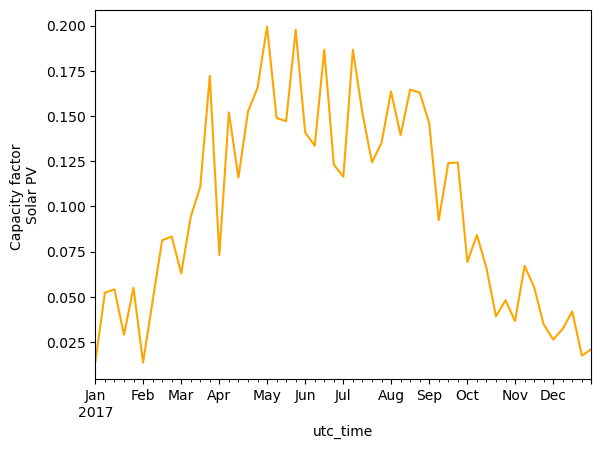
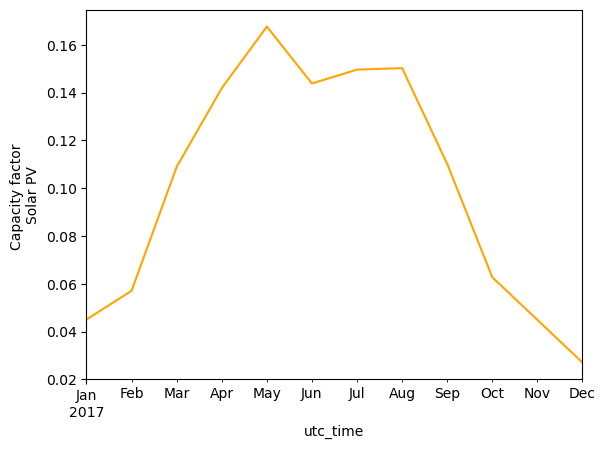
monthly_mean_pv.plot(kind='line', ylabel='Capacity factor \nSolar PV', color='orange')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nSolar PV'>
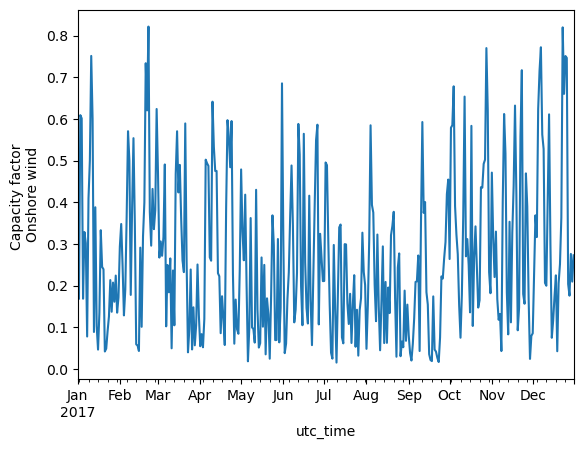
daily_mean_wind.plot(kind='line', ylabel='Capacity factor \nOnshore wind')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nOnshore wind'>
weekly_mean_wind.plot(kind='line', ylabel='Capacity factor \nOnshore wind')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nOnshore wind'>
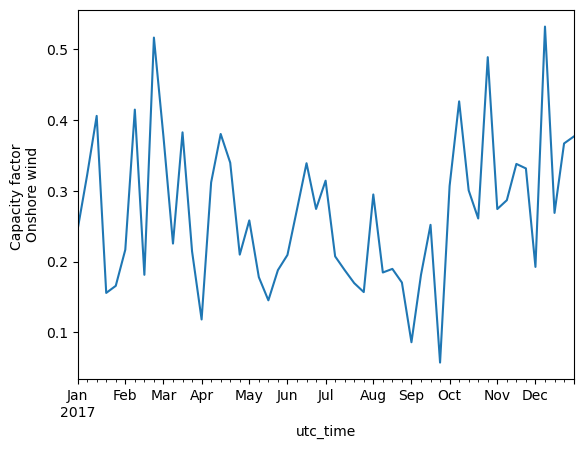
monthly_mean_wind.plot(kind='line', ylabel='Capacity factor \nOnshore wind')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nOnshore wind'>
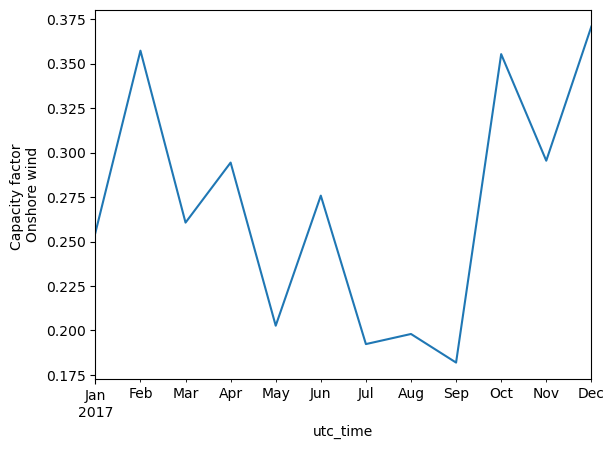
Based on the figures shown above the following trends are seen:
Solar PV has a clear daily pattern seen on the capacity factor plot for the first two weeks of the year. High capacity factors are seen in the middle of the day and zero at night.
Solar PV furthermore, has a clearly seasonal pattern, with high capacity factors in summer, and lower in winter.
Analysing the daily average capacity factor of wind, fluctuations showing approximately a weekly period are seen.
A slightly seasonal pattern is also seen for wind, with more wind in the winter and less in the summer.
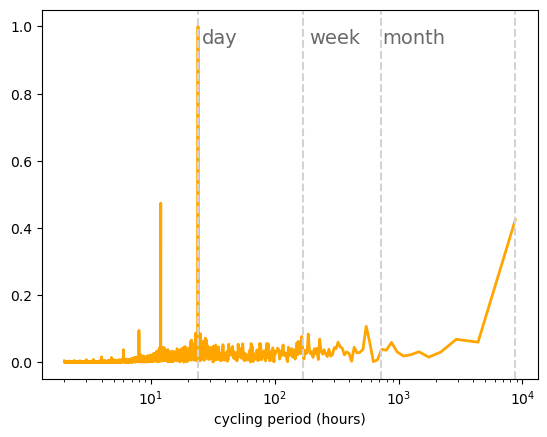
3) One useful way of investigating the previous question is to calculate the Fast Fourier Transform (FTT) power spectra of the time series. Do so and plot the power spectra for wind and solar capacity factor time series. Are these results in agreement with steps 1 and 2?
The function fft.fft() is used to calculate the Fast Fourier Transform \(a_{\omega}=\int^T_0 X(t) e^{i \omega t}dt\) where \(X(t)\) is the time series (wind or solar) that we are analysing.
The power spectra \(\| a_{\omega}\|^2\) are plotted to identify the dominant frequencies.
t_sampling=1 # sampling rate, 1 data per hour
x = np.arange(1,8761, t_sampling)
y = data_pv.loc['2017-01-01':'2017-12-31'][country]
n = len(x)
y_fft = np.fft.fft(y)/n #n for normalization
frq = np.arange(0,1/t_sampling,1/(t_sampling*n))
period = np.array([1/f for f in frq])
/var/folders/zg/by4_k0616s98pw41wld9475c0000gp/T/ipykernel_76813/3780475453.py:7: RuntimeWarning: divide by zero encountered in scalar divide
period = np.array([1/f for f in frq])
We plot the power spectra as a function of the period (1/frequency).
plt.semilogx(period[1:n//2],
abs(y_fft[1:n//2])/np.max(abs(y_fft[1:n//2])),
color='orange',
linewidth=2)
plt.xlabel('cycling period (hours)')
#We add lines indicating day, week, month
plt.axvline(x=24, color='lightgrey', linestyle='--')
plt.axvline(x=24*7, color='lightgrey', linestyle='--')
plt.axvline(x=24*30, color='lightgrey', linestyle='--')
plt.axvline(x=8760, color='lightgrey', linestyle='--')
plt.text(26, 0.95, 'day', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*7+20, 0.95, 'week', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*30+20, 0.95, 'month', horizontalalignment='left', color='dimgrey', fontsize=14)
Text(740, 0.95, 'month')
t_sampling=1 # sampling rate, 1 data per hour
x = np.arange(1,8761, t_sampling)
y = data_wind.loc['2017-01-01':'2017-12-31'][country]
n = len(x)
y_fft = np.fft.fft(y)/n #n for normalization
frq = np.arange(0,1/t_sampling,1/(t_sampling*n))
period = np.array([1/f for f in frq])
/var/folders/zg/by4_k0616s98pw41wld9475c0000gp/T/ipykernel_76813/2483825668.py:7: RuntimeWarning: divide by zero encountered in scalar divide
period = np.array([1/f for f in frq])
plt.semilogx(period[1:n//2],
abs(y_fft[1:n//2])/np.max(abs(y_fft[1:n//2])),
linewidth=2)
plt.xlabel('cycling period (hours)')
#We add lines indicating day, week, month
plt.axvline(x=24, color='lightgrey', linestyle='--')
plt.axvline(x=24*7, color='lightgrey', linestyle='--')
plt.axvline(x=24*30, color='lightgrey', linestyle='--')
plt.axvline(x=8760, color='lightgrey', linestyle='--')
plt.text(26, 0.95, 'day', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*7+20, 0.95, 'week', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*30+20, 0.95, 'month', horizontalalignment='left', color='dimgrey', fontsize=14)
Text(740, 0.95, 'month')
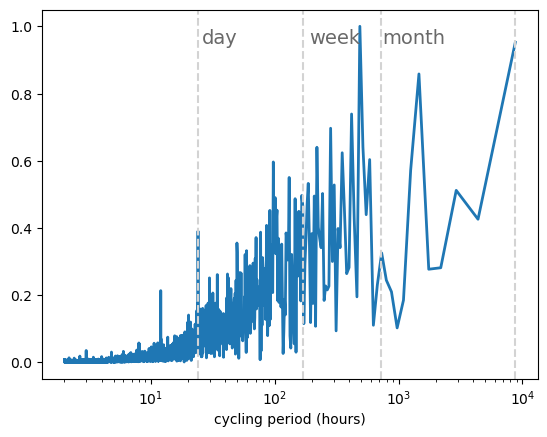
Solar PV main fluctuations show a daily cycle, while onshore wind shows significant fluctuations in the synoptic timescale (with a frequency of around one week)
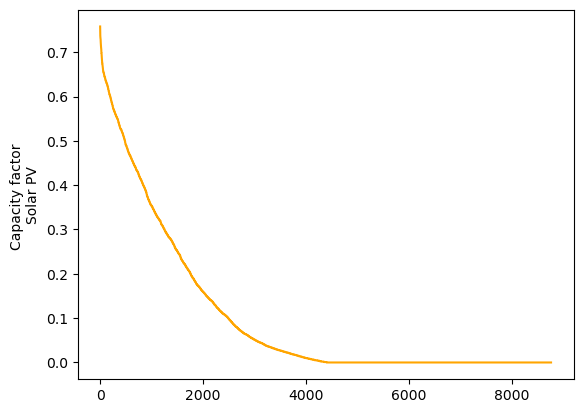
4) Plot the duration curve (sorted capacity factors values) for every technology. What percentage of the potential wind and solar energy will be lost if the potential generation is curtailed for the 10 hours with the highest capacity factors? What if curtailment affects the 100 hours with the highest capacity factors?
Solar PV#
duration_pv = data_pv.loc['2017-01-01':'2017-12-31'][country].sort_values(ascending=False,ignore_index=True)
duration_pv.plot(kind='line', ylabel='Capacity factor \nSolar PV', color='orange')
<Axes: ylabel='Capacity factor \nSolar PV'>
def curtailment_loss(duration_data, hours):
full_load_hours_per_year = sum(duration_data)
curtailment_loss = sum(duration_data[:hours])/full_load_hours_per_year
print('{:.1f} % annual production is lost if the {} hours with highest capacity factor are curtailed'.format(curtailment_loss*100,hours))
print('PV curtailment loss')
curtailment_loss(duration_pv,10)
curtailment_loss(duration_pv,100)
PV curtailment loss
0.8 % annual production is lost if the 10 hours with highest capacity factor are curtailed
7.6 % annual production is lost if the 100 hours with highest capacity factor are curtailed
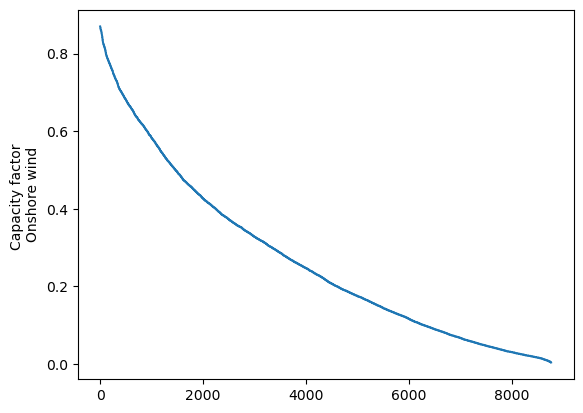
Onshore wind#
duration_wind = data_wind.loc['2017-01-01':'2017-12-31'][country].sort_values(ascending=False,ignore_index=True)
duration_wind.plot(kind='line', ylabel='Capacity factor \nOnshore wind')
<Axes: ylabel='Capacity factor \nOnshore wind'>
print('Wind curtailment loss')
curtailment_loss(duration_wind,100)
curtailment_loss(duration_wind,1000)
Wind curtailment loss
3.5 % annual production is lost if the 100 hours with highest capacity factor are curtailed
29.4 % annual production is lost if the 1000 hours with highest capacity factor are curtailed
The duration curves for solar and wind are fundamentally different. Solar PV includes more than 4000 hours of zero capacity factors (the nights!) and the maximum capacity factor is 0.7 (It is very difficult for the entire Denmark to have a clear sky simultaneously). Wind duration curve includes a very low number of hours with zero capacity factor and a maximum of 0.9
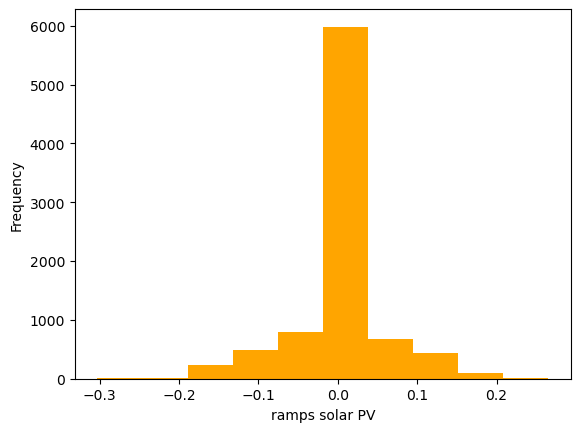
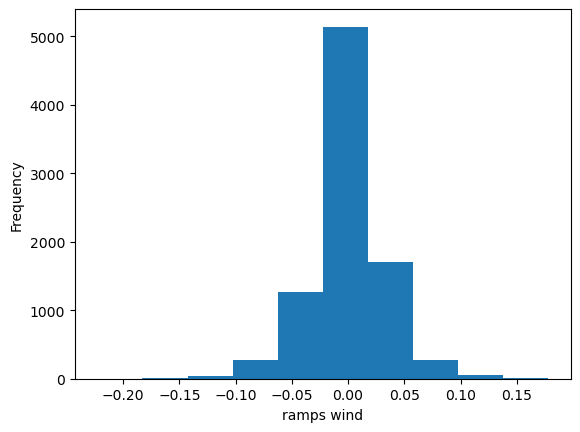
5) Calculate the ramps for every technology for every hour of the year. We define the ramp in hour \(t\) as the difference between the capacity factor in hour \(t\) and the capacity factor in the previous hour \(t-1\). Plot the distribution of ramps for wind and solar. Which technology has the higher variability?
ramps_pv = data_pv.loc['2017-01-01':'2017-12-31'][country].diff()
ramps_pv.plot(kind='hist', xlabel='ramps solar PV', color='orange')
<Axes: xlabel='ramps solar PV', ylabel='Frequency'>
ramps_wind = data_wind.loc['2017-01-01':'2017-12-31'][country].diff()
ramps_wind.plot(kind='hist', xlabel='ramps wind')
<Axes: xlabel='ramps wind', ylabel='Frequency'>
6) Let us now look at the interannual variability. For every technology, calculate the annual capacity factor for the most recent year for which you have data. Then, calculate the annual capacity factor for every year for which you have data. Estimate the average value for all the years and the year-to-year variance.
Solar PV#
annual_mean_pv = data_pv[country].resample('YE').mean()
annual_mean_pv.plot(kind='line', ylabel='Capacity factor \nSolar PV', color='orange')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nSolar PV'>
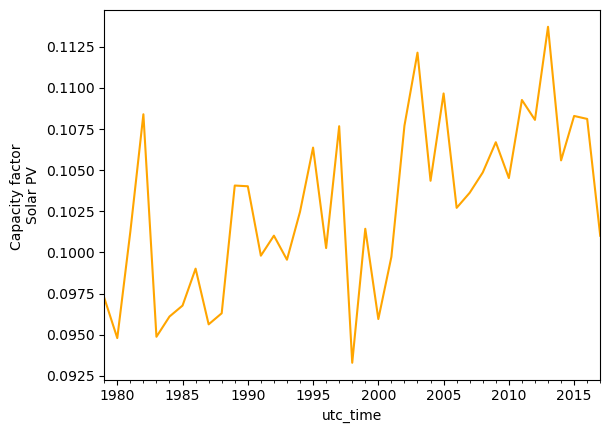
print('Average annual mean {:.2f}, \nNormalised standard deviation {:.2f}'.format(annual_mean_pv.mean(),annual_mean_pv.std()/annual_mean_pv.mean()))
Average annual mean 0.10,
Normalised standard deviation 0.05
Onshore wind#
annual_mean_wind = data_wind[country].resample('YE').mean()
annual_mean_wind.plot(kind='line', ylabel='Capacity factor \nOnshore wind')
<Axes: xlabel='utc_time', ylabel='Capacity factor \nOnshore wind'>
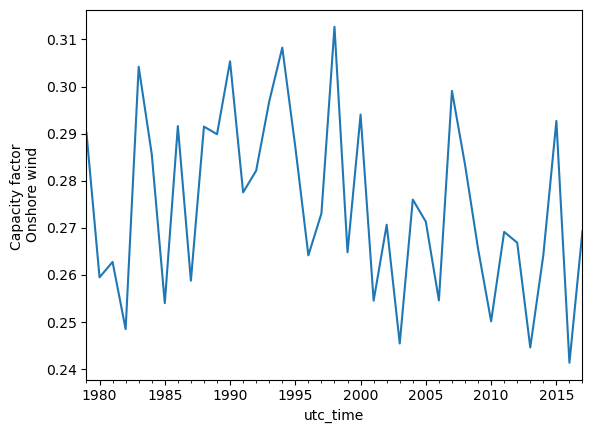
print('Average annual mean {:.2f}, \nNormalised standard deviation {:.2f}'.format(annual_mean_wind.mean(),annual_mean_wind.std()/annual_mean_wind.mean()))
Average annual mean 0.27,
Normalised standard deviation 0.07
Repeat steps 1 to 5 for the electricity and heating demand time series.
Data import#
data_el = pd.read_csv('data/electricity_demand.csv',sep=';')
data_el.index = pd.DatetimeIndex(data_el['utc_time'])
data_heat = pd.read_csv('data/heat_demand.csv',sep=';')
data_heat.index = pd.DatetimeIndex(data_heat['utc_time'])
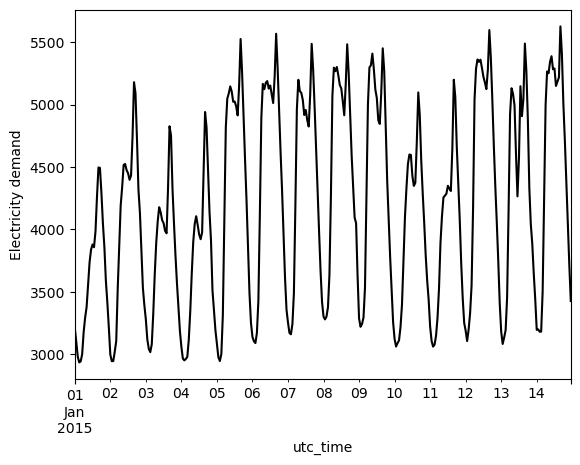
1) Plot of demand throughout two weeks#
data_el.loc['2015-01-01':'2015-01-14'][country].plot(kind='line', ylabel='Electricity demand', color='black')
<Axes: xlabel='utc_time', ylabel='Electricity demand'>
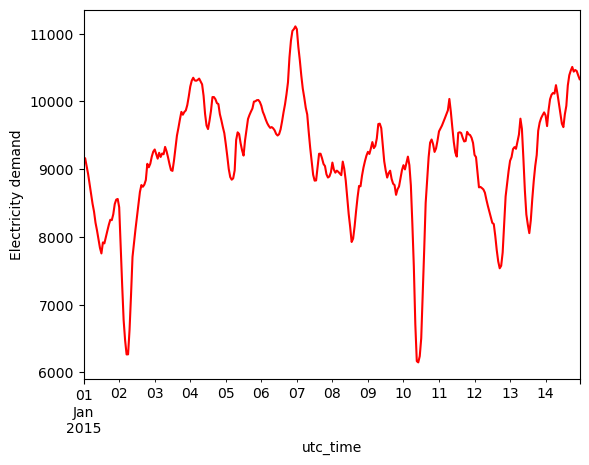
data_heat.loc['2015-01-01':'2015-01-14'][country].plot(kind='line', ylabel='Electricity demand', color='red')
<Axes: xlabel='utc_time', ylabel='Electricity demand'>
### 1) Plot of daily, weekly, annual demand
# Daily
daily_mean_el = data_el.loc['2015-01-01':'2015-12-31'][country].resample('D').mean()
daily_mean_heat = data_heat.loc['2015-01-01':'2015-12-31'][country].resample('D').mean()
# Weekly
weekly_mean_el = data_el.loc['2015-01-01':'2015-12-31'][country].resample('W').mean()
weekly_mean_heat = data_heat.loc['2015-01-01':'2015-12-31'][country].resample('W').mean()
# Monthly
monthly_mean_el = data_el.loc['2015-01-01':'2015-12-31'][country].resample('ME').mean()
monthly_mean_heat = data_heat.loc['2015-01-01':'2015-12-31'][country].resample('ME').mean()
daily_mean_el.plot(kind='line', ylabel='demand', color='black')
daily_mean_heat.plot(kind='line', color='red')
<Axes: xlabel='utc_time', ylabel='demand'>
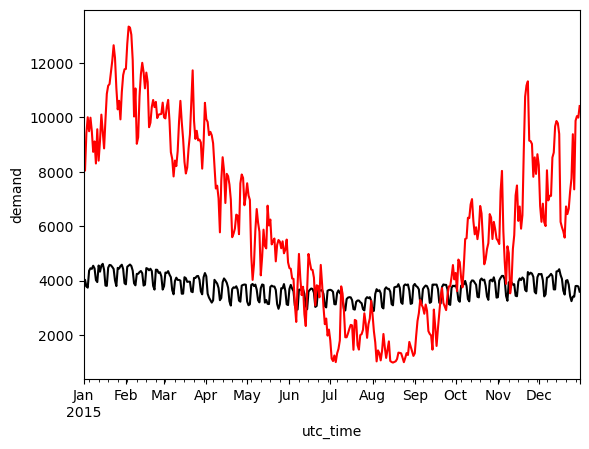
weekly_mean_el.plot(kind='line', ylabel='demand', color='black')
weekly_mean_heat.plot(kind='line', color='red')
<Axes: xlabel='utc_time', ylabel='demand'>
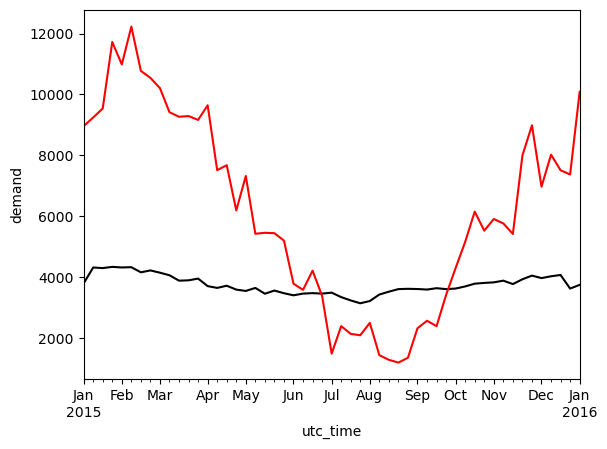
monthly_mean_el.plot(kind='line', ylabel='demand', color='black')
monthly_mean_heat.plot(kind='line', color='red')
<Axes: xlabel='utc_time', ylabel='demand'>
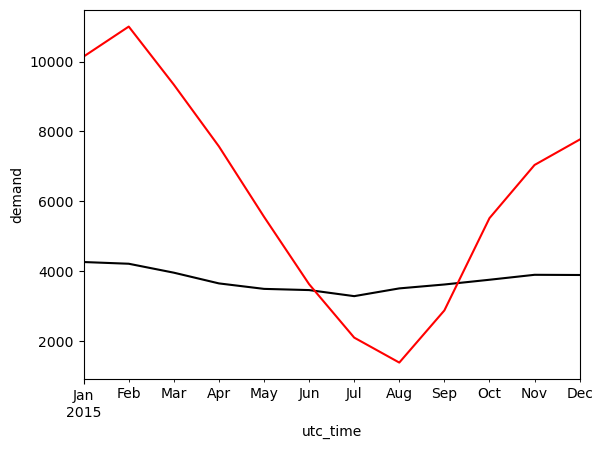
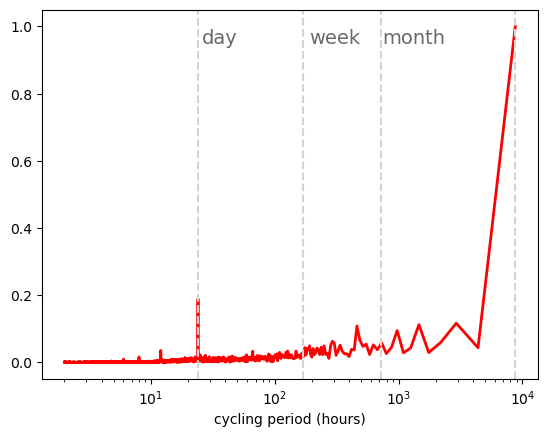
Fast Fourier power spectra#
t_sampling=1 # sampling rate, 1 data per hour
x = np.arange(1,8761, t_sampling)
y = data_el.loc['2015-01-01':'2015-12-31'][country]
n = len(x)
y_fft = np.fft.fft(y)/n #n for normalization
frq = np.arange(0,1/t_sampling,1/(t_sampling*n))
period = np.array([1/f for f in frq])
plt.semilogx(period[1:n//2],
abs(y_fft[1:n//2])/np.max(abs(y_fft[1:n//2])),
color='black',
linewidth=2)
plt.xlabel('cycling period (hours)')
#We add lines indicating day, week, month
plt.axvline(x=24, color='lightgrey', linestyle='--')
plt.axvline(x=24*7, color='lightgrey', linestyle='--')
plt.axvline(x=24*30, color='lightgrey', linestyle='--')
plt.axvline(x=8760, color='lightgrey', linestyle='--')
plt.text(26, 0.95, 'day', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*7+20, 0.95, 'week', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*30+20, 0.95, 'month', horizontalalignment='left', color='dimgrey', fontsize=14)
/var/folders/zg/by4_k0616s98pw41wld9475c0000gp/T/ipykernel_76813/1496012896.py:7: RuntimeWarning: divide by zero encountered in scalar divide
period = np.array([1/f for f in frq])
Text(740, 0.95, 'month')
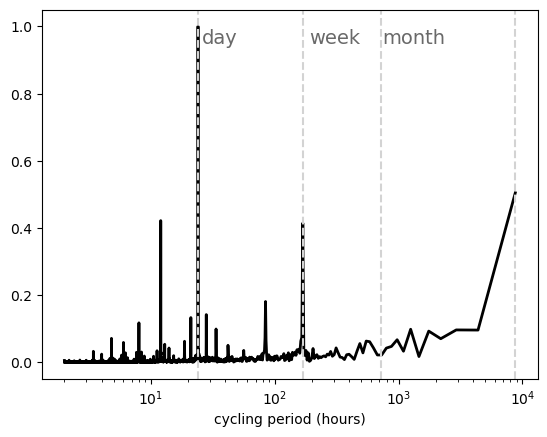
t_sampling=1 # sampling rate, 1 data per hour
x = np.arange(1,8761, t_sampling)
y = data_heat.loc['2015-01-01':'2015-12-31'][country]
n = len(x)
y_fft = np.fft.fft(y)/n #n for normalization
frq = np.arange(0,1/t_sampling,1/(t_sampling*n))
period = np.array([1/f for f in frq])
plt.semilogx(period[1:n//2],
abs(y_fft[1:n//2])/np.max(abs(y_fft[1:n//2])),
color='red',
linewidth=2)
plt.xlabel('cycling period (hours)')
#We add lines indicating day, week, month
plt.axvline(x=24, color='lightgrey', linestyle='--')
plt.axvline(x=24*7, color='lightgrey', linestyle='--')
plt.axvline(x=24*30, color='lightgrey', linestyle='--')
plt.axvline(x=8760, color='lightgrey', linestyle='--')
plt.text(26, 0.95, 'day', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*7+20, 0.95, 'week', horizontalalignment='left', color='dimgrey', fontsize=14)
plt.text(24*30+20, 0.95, 'month', horizontalalignment='left', color='dimgrey', fontsize=14)
/var/folders/zg/by4_k0616s98pw41wld9475c0000gp/T/ipykernel_76813/3748597511.py:7: RuntimeWarning: divide by zero encountered in scalar divide
period = np.array([1/f for f in frq])
Text(740, 0.95, 'month')
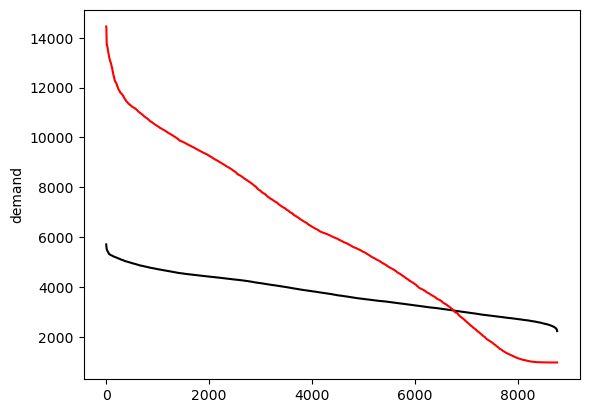
Duration curves#
duration_el = data_el.loc['2015-01-01':'2015-12-31'][country].sort_values(ascending=False,ignore_index=True)
duration_heat = data_heat.loc['2015-01-01':'2015-12-31'][country].sort_values(ascending=False,ignore_index=True)
duration_el.plot(kind='line', ylabel='demand', color='black')
duration_heat.plot(kind='line', ylabel='demand', color='red')
<Axes: ylabel='demand'>
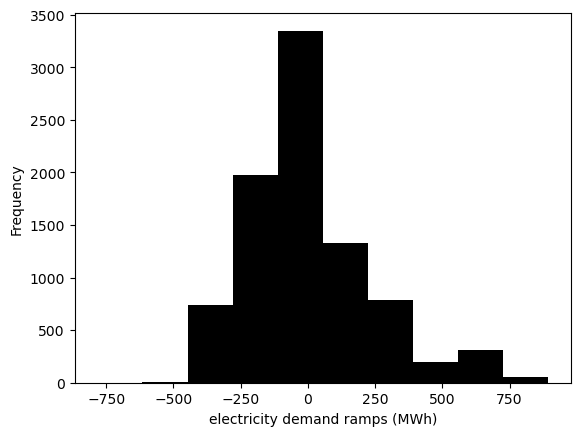
Ramps#
ramps_el = data_el.loc['2015-01-01':'2015-12-31'][country].diff()
ramps_el.plot(kind='hist', xlabel='electricity demand ramps (MWh)', color='black')
<Axes: xlabel='electricity demand ramps (MWh)', ylabel='Frequency'>
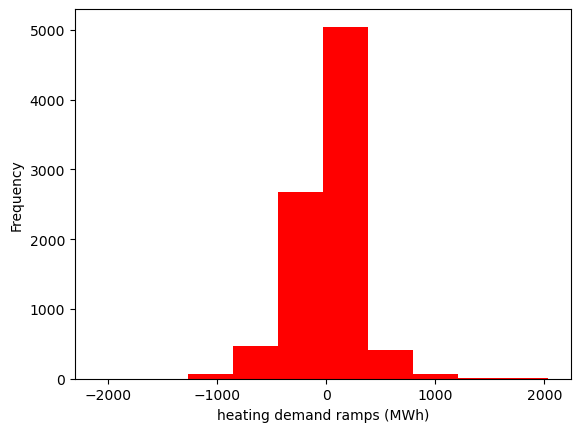
ramps_heat = data_heat.loc['2015-01-01':'2015-12-31'][country].diff()
ramps_heat.plot(kind='hist', xlabel='heating demand ramps (MWh)', color='red')
<Axes: xlabel='heating demand ramps (MWh)', ylabel='Frequency'>